This is part 2 in the MacPy3D series. Check out the MacPy3D tag for all posts.
Generally when making things in 3D, we like to talk about objects. For instance a cube, or a pyramid. When making a 3D modelling library, it therefore pays to have a very good idea of what an object actually is, and what different kinds of objects one can have. Also, it seems that other programs use the term manifold object; I have done my best to explain what that means and what MacPy’s thoughts about this are.
Dimensions and object types
Let’s start by looking at the world in one dimension less. What are the objects we can find in lower dimensions. Both because it’s easier to show what’s going on (since you’re reading this on a 2D device) and because 2D objects are easier to imagine.

The simplest object we can have is a point. It is 0-dimensional, has no length and no width. Things get more interesting if we have more than 1 point.
Either the two points are on top of each other (they have the same coordinates), in which case the result is still 0D. We can also call this 0.0D, meaning that we have a 0D object in 0D space.
If the points are not op top of each other, but they are on aline (note that 2 points that are not op top of each other always are on aline), we can call this a pointline, and call the resulting dimensionality 0.1D, 0 dimensional objects in a 1 dimensional space. As soon as we have more points and 1 of the points is not on the same line as the others, we speak of a 0.2D pointmap, 0 dimensional objects in 2 dimensional space.
A line (or technically line segment), is a simple 1D (or 1.1D) object. The same goes for what I called a multiline. Two or more line segments that are either overlapping, connected or unconnected, however are on 1 line.
If two or more line segments are not on 1 line, they are 1 dimensional objects in 2D space: 1.2D. I called them polylines above — it doesn’t matter if the line segments connect head-to-tail, form a loop, cross; as soon as you have multiple line segments not on the same line, it’s a polyline.
One step further, a proper 2D (2.2D) object, is the polygon. Note that the difference between polylines and a polygon is not whether it’s a closed loop; polylines are line segments, whereas the polygon is the area or surface enclosed. This is an important difference to keep in mind going forward, even though in real life we usually define a polygon as a list of coordinates for its corners, and then imply that we need the contained area. Note however that we could also imagine polygons where the area we care about is actually the infinite plane except for the little area enclosed by the polygon. More on different types of polygons later.
Important for the area above is to understand that there are different types of objects in dimensions 0, 1 and 2, and that it makes sense to speak about something like multiple 1D objects in a 2D space (what I called a 1.2D object).
Shape vs line representation
Looking at the list of objects above, it should be noted that I could have made a completely different categorisation, that goes something like this: straight line, square, triangle, parallelogram, etc. This would make sense if we would want MacPy to deal with shapes.

For instance, if we have the drawing of a house, we could say it’s a square with a triangle on top, and store it as such internally (a Square object with an origin and width parameter and a Triangle object with some parameters: Shape representation). Alternatively we could say that it’s just a polyline (e.g. a list of Line objects, each with a start and end parameter; this latter method we call the Line representation.
Obviously it’s easy to switch from shape representation to line representation; the other direction is much harder if not impossible. So it seems a good idea to keep the shape representation as long as possible. However say that we want to do some operations on the objects (for instance, given a new triangle, T, how many lines of our figure does T cross), in the shape representation we would have to create code to calculate intersections between triangles and triangles, and triangles and squares. Although each of these individual functions are very easy, the number of functions explodes very quickly, to support N different shapes, we need to create N² functions per operation. In line representation we just create 1 function, multilines intersecting other multilines — a function we’d have to write anyways, since in shape representation you may also have individual line segment shapes.
In 3D, the number of shapes grows quickly, and the type of operations are more complex. Also, many times we combine 2 shapes into a new one (by doing a union, difference or intersection of 2 shapes), which will have many unique properties. Finally, thanks to 3D scanners, we often deal with shapes that are not basic shapes, but are just the 3D equivalent of lines to start of with.
For these reasons, in MacPy3D, I have chosen to use the 3D equivalent of line representation, called Boundary Representation (B-Rep; the exact details of how we do this follow later). The shape representation equivalent in 3D is known as Constructive Solid Geometry (CSG), and this is the system used by OpenSCAD (as far as I have been able to find out). I don’t want to say that this is always the better solution, and maybe over time I will change my mind and move MacPy3D towards CSG as well, but for now MacPy3D uses B-Rep.
So far all shapes we talked about can actually be deconstructed into lines. We skipped over curved lines and areas, such as arcs and circles. For now in MacPy3D, we only work with straight lines, approximating curves by small straight sections (with settings to control how many sections we want) — in the same way we can approximate curved areas and (later) 3D objects. Later versions may change this and start supporting curves — life in 3D is already hard enough in a first version without curved stuff.
We need to talk about floating point precision
Something we’ve glanced over so far is how we actually store data. Regardless of whether we use a shape or line representation, we have to deal with coordinates. Imagine a square with coordinates: (0, 0), (2, 0), (2, 2), (0, 2). If we rotate this square 45 degrees (around (0, 0)), math tells us that the new coordinates should be (0, 0), (√2, -√2), (2√2, 0), (√2, √2). Easy enough to write down, however we cannot store √2 in a computer — typically we store numbers in floating point values. We could write √2 as 1.41 in 3 digits, or 1.4142135623730951 if I wanted to use 17 digits. Similarly we can choose how many bits we want our floating point numbers to be; but no matter how many digits, or bits, we use, we can never write out √2 exactly.
Side note: it’s tempting to think if we could work around this by using something smarter than floats, or use shape representation and just say “this square rotated 45 degrees”. I have considered this for a while, but this would be a huge project in itself, and probably one would not end up with a very helpful (or fast) library (maybe one day…). So for now, floats it is.
The accuracy of your average float is dependent on the type of float we use. In the early days of computing people had different names for how many bits a single float used: half (16 bits), float (32 bits), double (64 bits), quad (128 bits); these days it’s more common (and explicit) to talk about float16, float32, etc; in this blog I will use float as the concept of a float without any particular accuracy, and float32 etc when I want to talk about accuracy. I could write √2 as 1.41 in 3 digits (giving me 0.01 precision), however the same 3 digits for √200 = 14.1, gives me 0.1 precision. Similarly floats have precision dependent on how large a number they store. To give you an idea, for a number between 1 and 2, a float32 could store something like 7 decimals (giving 0.0000001 accuracy), for numbers between 1 and 2 million there is only 1 decimal (0.1 accuracy). For float64 these numbers are 16 decimals for numbers between 1 and 2 (0.0000000000000001 accuracy) and 10 decimals for numbers between 1 and 2 million (0.0000000001 accuracy).
The exact accuracy plays a role when we choose exactly which floats we want to use in our library, however for now it’s enough to understand that, no matter the accuracy, there is no way to store √2 exactly, and the accuracy depends on the size of the number.
At many times during this post (and later ones), I will want to show you the problems we run into with this precision “issue”. In examples I will usually resort to an artificial datatype that has just 2 or 3 digits precision. Obviously real floats have many more bits, and their accuracies are powers of 2, not powers of 10 (even though there are decimal floating point formats, as far as I know they are not supported in numpy, and I expect them to be slower than binary ones), but anything that I can show on the “2 digit precision scale”, also can happen on the 64 bit scale; just, it’s much harder for a human to spot the issues in large numbers, and it may happen less often, meaning that it’s much much harder to debug. A 3 digit system will have 3 significant digits (e.g. 0.000123, or 123000); occasionally I will also talk about a 3 decimals system, in this case I mean something with 3 digits after the dot (so 0.123, or 123123.123).
As a side note, if you want to exprience floating point precision messing up your calculations, just type 2.0**53 + 1 — 2.0**53 into a python prompt and you will see that the + 1 was too small for the floating point precision to store.
We already met a situation where floating point precision may make a difference. Remember that we described a pointline as a 0.1D object, a 0D object in 1D space. If we want to know if a group of points is a pointline, all we have to do is determine if they are all on the same line (the exact math I leave as exercise for the reader). Now, imagine 3 points, (0, 0), (3, 9), (4, 12). They clearly are on 1 line, and form a pointline. Now, let’s say we scale the whole set by a factor ⅓. Scaling is an operator that should leave the points on 1 line: (0, 0), (1, 3), (1⅓, 4), however the last point will be represented as (1.3, 4) (if we assume 2 digits precision). Now, the points are no longer exactly on 1 line, and technically form a pointcloud, not a pointline.
If we care (for whatever reason; later we will see examples where we do care) if things are a pointline or pointcloud, we now have to make a choice; do we say that our scaling operation made a pointcloud from a pointline, or do we try to be smart and say “a pointline is a collection of points that all lie on 1 line within rounding distance”. The second solution feels good, however what does this mean for when we scale the scaled-down line by 3. Since 1.3⨉3 = 3.9, we would come to (0, 0), (3, 9), (3.9, 12), which again does not describe a pointline, even within our renewed definition that a pointline should be on one line within rounding distance. In this case we could consider adding some magic to our scale function, saying that if the source is a pointline, the scaled up version should be fixed to be a pointline as well, and therefore turning the last element again into (4, 12). It feels like we solved our problem, however this means that if we take a different setup, a pointcloud of the points (0, 0), (3, 9), (3.9, 12) and scale it by ⅓ and then 3, it now became a pointline. No matter what you try, the result of limited precision is that you lose information, one way or another.
One solution to this could be to change the coordinate system to something that persists the properties we care about. For instance, we could say that all points on this line just have 1 parameter, t, and that to get to “regular” coordinates you would have to do (1, 3)t. This means that our original line has coordinates 0, 3, 4, and the scaled line 0, 1, 1.3. It still means that rounding took place, but at least all points still (clearly, per definition) form a line. Sometimes this is possible, sometimes not.
(side note: as another smart plan, you could decide to store with the (1.3, 4) that it’s actually (4, 12)/3, which means that upon multiplication you end up with (4, 12) again. This works well in this case, however remember (as we said above) that we don’t just deal with scalings, but with square roots, and rotations (meaning sin/cos). The solution of storing that 1.3 is actually 4/3 and keeping that consistently is as much work as coming up with an exact math library for computers, including solvers, etc.)
There are 2 takeaways from this section that will be important in the rest of this story:
- We always have to worry about numbers not being exact. If we ever compare 2 numbers exactly, we have to make sure we know for sure that we can, that there are no rounding issues around (and, as we will see throughout this series, this is the exception rather than the rule).
- It usually does not make sense to ask if a point is exactly on the edge (of a polygon; or later, of a 3D object).Given 2 points that form the side of the polygon, there are (mathematically) infinitely many points that lie exactly on that line. However if we know that all coordinates we see are in some way rounded down, there is, in real computer-life, a small area around the polygon’s edge for which we really don’t know if the requested point was inside or outside (or exactly on the line). For example, if we have a polygon edge from (1.1, 1.1) to (1.9, 1.9), and we want to know if (1.5, 1.5) is inside or outside, we could argue that mathematically it’s exactly on the edge. However (1.5, 1.5) could be a rounded down version of (1.51, 1.50), which is inside (if we define south-west inside), or it could be (1.49, 1.50), which is outside. Or even if we know for sure it’s exactly (1.5, 1.5), how do we know that (1.1, 1.1), the startpoint, is not actually (1.09, 1.10)?
Side note: should we be using floats at all (TL;DR: yes, for now)
Floats are amazing numbers in lots of situations, they can be extremely large, and extremely small, all within the same bits that gives an integer a very limited range. Without wanting to dive into details on how floats work, the best analogy is to imagine that floats save a certain number of significant figures (actually, they do exactly that — with some magic for not-a-number and infinite values, and a limited range for the exponent, however they have significant bits rather than digits).
Let’s say we have a number system with 4 significant digits, and the (10 base) exponent has a range from -4 to 5. This means we can represent numbers like 123400000, 123400, 1234, 12.34, or 0.1234 — any number between 0.0001 and 999900000, as long as there are at most 4 places between the first and the last non-zero. Note that in this system each number would need 5 digits storage space, 4 for the significant number, and 1 for the (exponent + 4).
This is an amazing number system in situations where we want lots of precision when close to 0, and need less precision in the higher numbers; very useful for what you want in many situations (measurements, factors in machine learning, etc). It also means that multiplying is quite easy without much loss of accuracy; e.g. if you have 364, you can multiply it by 1371243 (=499374148≈499300000), divide again by 1371243 and we’re back at 364; However if we try to add things, it’s a different picture: 364+1371243=1371607≈1372000. Subtract 1371907 and we’re left with 757, not just a small inaccuracy, but a more than twice the original value.
As an alternative to this system we could use the 5 digits we have to always represent thousands, hundreds, tens, ones, and one-tenths. This means we have every 0.1 step between 0.0 and 9999.9 available. This kind of number is usually called decimal in programming. It’s easy to see that multiplying 364 and 1371243 (or even 1371.2, which is a valid number in this system) will directly overflow the decimal. However as long as we keep the results between 0 and 9999.9, any addition and subtraction will have exact results, and a + b — b will always be exactly a.
The main reason why the two act differently for addition is that float has an accuracy that scales with the size of the number (one can also say: the accuracy is a more-or-less constant percentage of the value), whereas a decimal has a constant value for the accuracy.
For every piece of data a good programmer will explicitly consider which of these number systems they want to use. In modelling, adding/subtracting (for coordinates) is moving objects around in space, whereas scaling is multiplying. It feels to me that in modelling, moving happens a lot more, and therefore a decimal datatype would be preferable (also see the later discussion about epsilon). However, there are 2 good reasons to choose floats in the end. For one, nowadays a lot of hardware is optimised for floating point operations, so using floating point will be faster. Secondly, even though python has a Decimal type, numpy (which will do all the heavy lifting in MacPy3D) does not.
Personally I do feel that possibly some of the issues we’re going to run into in the future could be circumvented by using decimal rather than float; on the other hand, we will have access to large floats (like float64 and float128) and these floats tend to keep a very good accuracy over a longer interval.
Polygons
Let’s go back to the 2.2D objects we discussed: polygons. From a programmers point of view it’s tempting to say that a polygon is just a list of points. Draw a line from point A to B to C etc and back to A and the area in between is your polygon. However life is not that simple. There are lots of different types of polygons, some we like, some we don’t (but have to live with) and some we can disallow.
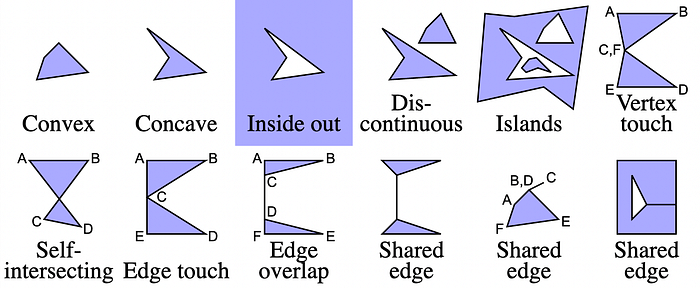
- Convex polygon: A polygon is convex if every corner is ≤ 180 degrees. Said differently, if I were to put a rubber band around the polygon, it would form exactly around the edges. Said even differently, any line I can draw between 2 points will either be on the edge or be completely inside the polygon.
- Concave polygon: A polygon is concave as soon as one of the corners is larger than 180 degrees — or, said differently, any non-convex polygon.
- Inside out polygon: Generally when we draw a polygon, we intend the enclosed area to be the area we mean, however there is no reason why we could not mean the outside.
- Discontinuous polygon: Even though we could easily describe this as being 2 polygons, there is sometimes an advantage to consider it to be a single polygon.
- Islands polygon: There is no reason why the inside of a polygon cannot contain holes — or these holes contain positive holes in turn, etc. Also here it is sometimes useful to consider this to be a single polygon.
- Vertex touch polygon: This polygon could be thought of as 2 polygons that share a single point (named both C and F in the drawing). Just as with the discontinuous polygon, we could describe this as 2 separate polygons, but sometimes we want to describe it as a single polygon. We call the polygon Vertex Touch, because we can imagine the left and right side of the polygon touching in the vertex C/F.
- Self-intersecting polygon: A connected list of points can intersect itself. It doesn’t matter in this case if we have a vertex X in the center (meaning the list would be A-B-X-C-D-X-A) or not, the important thing is that by self-intersecting, there is no consistent orientation (meaning that you cannot walk the polygon in such a way that the inside is always left (or always right) of your direction of traveling. Note that if the polygon would be A-B-X-D-C-X-A, it would be a Vertex touch polygon, and it would be allowed as polygon.
Crossing polygons lead to all kinds of problems (and even more so soon in 3D objects), and therefore we would want to avoid them (this means: in MacPy3D they are not allowed and will result in an error). - Edge touching polygon: This polygon looks a lot like the Vertex touch polygon; the key difference is that the point C is visited only once (the point C is right on the edge A-E). Since C is not to the left of A-E, the polygon does not self-intersect. However, as we discussed above, in the Floating Point Precision section, due to precision errors, there is no such thing as “the edge of the polygon”; practically speaking, if we scale or rotate the polygon, C could, due to rounding errors, end up on the wrong side of A-E, thereby creating a self-intersection. Since we don’t want a valid polygon becoming invalid by something simple as a rotation or scaling, this type of polygon is not allowed (obviously this could easily be fixed by adding a point F that coincides with C, making it a vertex touching polygon, however this is not something we want to do automagically).
The attentive reader will see a contradiction here: how can we disallow an edge-touching polygon, if we just claimed that polygons don’t have sharp edges. In practice this means that we need to disallow anything that comes close to an edge-touching polygon (what “close” means is something we discuss later).
Note that in the Vertex touch polygon we don’t have the floating point precision problem; Since C and F are the same point (or at least have the same coordinates), any operation on C will result in the same change in F. - Edge overlap polygon: Since the edge-overlap polygon is just a special case of the edge touching polygon (both C and D are on the edge A-F), this is not allowed.
- Shared edge polygons: Finally there are a number of shared edge polygons. These are polygons where a certain edge between 2 vertices is traversed twice, once in each direction. This results in a double edge, that either has “inside” on both sides or “outside” on both sides.
Since we define a polygon as an area (and not the line around the area), any shared edge is meaningless and should be removed. Because of this (and since it will lead to inconsistencies in the 3D situations later), we do not allow shared edge polygons.
Note that there are many other shared edge polygons possible, the three depicted are just examples.
The rules on which polygons are allowed and which are not allowed can be summarised in these three rules (note that in this list we assume that 2 vertices with the same coordinate are a single vertex):
- One must be able to write the polygon as a a list of lists of points, such that when the points of any inner list are traversed (coming back to the first after the last), the right side is always the inside (or active side) of the area. This disallows self intersection.
- Any vertex must be a minimal distance ε (epsilon) from any edge, except (obviously) an edge that starts or terminates in one of the vertices of that set. This disallows edge touch and edge overlap polygons.
- For any 2 vertices A and B, it is not allowed to have more than one edge between A and B. This disallows shared edge polygons.
Note that rule 2 introduces the concept of ε (epsilon). More on this in the next section.
Epsilon ε, or: how to deal with floating point inaccuracy
As I described above, we cannot really say where the border of a polygon is exactly. As a result, if we have a polygon (0, 0), (0, 2), (2, 2), (2, 0) — a square of size 2 — we cannot say whether the point (2, 1) is inside this polygon, outside the polygon, or right on the border. This is because (2, 1) could actually be (2.001, 1), or (1.999, 1), but this difference got lost in the “floating point (in)accuracy”. Also, who’s to say that the top-right corner is actually (2, 2) and not (1.999, 1.999), but it lost this accuracy.
It doesn’t take a lot of imagination to see that it could be very useful to ask the question “does point P lie within or outside polygon Y?”. As we discussed, we cannot give a definite answer for the cases where P is right on the border (or very very close to the border), however we would like to be able to say that (1, 1) clearly is inside the polygon, and (3, 3) clearly is outside. In order to do so, we need to define a cutoff, saying that if the point is less than a certain value from the (mathematical) edge, we cannot say if it’s actually in or out.
Even if you don’t buy that it’s useful to know if a point is inside or outside, remember that we had a rule 2 in the last section that says that no vertex can be within a distance ε of any edge (ε is the small greek letter epsilon, a symbol often used to mean “a very small but not zero amount”). We need this to make sure that a point is on a certain side of an edge, so that we’re sure that there is no self-intersecting going on.
A lower bound for ε must obviously be the smallest change that the underlying numerical system can support (known as machine epsilon). For instance, if our number system only keeps track of 1 decimal after the dot, our machine epsilon is 0.1. You can imagine that if you need to know at which side of the line (2.0, 0.0) (2.0, 2.0) lies the point (2.0, 1.0), you can imagine that the line actually was (1.950000001, 0.0) (1.950000001, 2.0) and the point (2.0499999999, 1.0), meaning they lie 0.1 apart. So choosing an ε that’s smaller than 0.1 makes no sense.
➥Rule 1: ε needs to be at least the size of the smallest change that the underlying number system can support.
So let’s say we put ε at this lower bound. Let’s take the example of the polygon (0, 0), (0, 2), (2, 2), (2, 0), and we’ll use a system that has 3 digits precision. So now if we want to know if (2, 1) is inside or outside, we can say “we don’t know since it’s less than ε (0.01) from the border. However as soon as we ask the question for (2.01, 1), which is the smallest step we can do to the right if we have 3 digits accuracy, there IS a definite answer (since the distance to the edge is not < ε). It’s tempting, but it will get us into difficulties. Imagine we move everything 10 to the right. We now have the square (10, 0), (10, 2), (12, 2), (12, 0), and the point (12.01, 1). However here ε is 0.1 (also: 12.01 will be rounded to 12.0 if we only have 3 digits). Obviously we don’t want a point that was outside the polygon become “undefined” just because we moved everything. In other words, if we were to choose ε such that it’s at the machine epsilon, we would get a different ε depending on where in the grid we are. This is unacceptable and therefore we need to add a rule 2:
➥Rule 2: ε must be independent of the coordinate.
Rule 1 and 2 combined means that ε must be at least the machine epsilon at the largest coordinate we can imagine. This is troublesome without some upper bound on what coordinates we like to support. Time to make some assumptions and choices.
To put an upper bound on coordinates, we have to imagine what the largest thing is that someone would want to build with this system, and then see what the largest coordinates are. First however, let’s discuss what a (1, 1, 1)-sized cube means in real world dimensions; in other words, what units do we make our models in.
For now I assume people will mostly use millimetres as units. Some may use centimetres or even metres, some imperials may use inches of feet. Of all these, millimetres are the smallest.
Now, what is the largest thing that someone would like to design. My 3D printer has a build volume of about 250x250x250mm, which would make 250 the maximum coordinate.
Some people want to think bigger though, maybe model cars, or bridges. Let’s for now say that nobody will even want to use MacPy3D to model anything larger than 10,000 km long (say a bridge from Ireland to New York), so this would mean that the largest coordinates we need to support is 10¹⁰≈2³⁰.
If we use a float64, the smallest difference that a float can encode at values around 2³⁰ is around 1.19⨉10⁻⁷, or 0.000000119, so our lower bound for ε would be ~2⨉10⁻⁷.
Side note: if you want to calculate this for yourself (not fool-proof, but works most of the time): (np.array([2**30], dtype="float64").view("int64") — 1).view("float64") — 2**30 .
Now we have our lower bound for ε, let’s look for an upper bound. Obviously having a value like 10 for ε would not work; since we have a demand that a vertex has to be more than ε from an edge, we would not be allowed to put vertices within 10 units (10 mm) from an edge, not very useful. We need to make sure that a vertex will not be put within ε of an edge, unless the author actually meant to put it on top of the edge for all practical purposes.
➥Rule 3: The upper bound for ε is lower than the minimal design resolution that a modeller may be working with.
However, there is something else to consider here. During modelling we may repeatedly perform certain operations on objects, and often these are affine transformations, such as translate, rotate, scale, mirroring and shearing. It’s impossible to guarantee that all operations on a valid polygon should return a new valid polygon (e.g. I can always scale by a factor that is so small that some vertex comes within an arbitrary ε from an edge). However, we do want to make sure that these operations, done with reasonable parameters, will work. If we scale something by 80% we don’t want the object to become invalid — the same goes for rotating and moving the object a couple of times, we don’t want ε to be so close to the design resolution that the rounding errors from some simple transformations results in any distance becoming less than ε. This means that people using MacPy3D will almost never run into this ε — these problems will only show up if someone has a (detailed) object and then scales by a factor 0.01 (for instance); this feels like something only an advanced user may do; in this case we can also explain exactly why this is a problem, and they should be able to resolve it easily.
➥Rule 3a: The upper bound for ε is considerably lower than the minimal design resolution that a modeller may be working with.
Modern desktop 3d printers claim to have a 100μm (0.1mm) resolution. Therefore I would argue that when designing things, one should not ever care about things that happen on the 10μm (0.01mm) scale. This means, in the worst case scenario, if someone uses metres as their unit, the design resolution is 0.00001, or 10⁻⁵. Recall that we said before that a lower bound for ε would be 2⨉10⁻⁷; from this we can see that, if using float64, we will be able to support maximum coordinates of 10¹⁰, with a design resolution of 2⨉10⁻⁵, and still have a factor 50 between smallest design resolution and machine epsilon over this range.
And if people want smaller design resolution, or larger structures, they can always choose different units for now.
Side note: what if we would want to use float32
It’s interesting to see if we could use float32s instead of float64. We have made some very generous assumptions for what is needed.
Whereas a float64 has about 17 orders of magnitude in machine epsilon (meaning that at sizes of 10¹⁰ it can store 10⁻⁷ accuracy; 10-(-7)=17), float32 has 7 orders of magnitude. If we assume units to always be millimetres, and we want 1000mm max coordinates (for a 1x1x1 metre build volume), the smallest changes that can be recorded are 0.0001, still allowing for an smallest design resolution of 10μm, and a factor 100 between that and smallest precision. So float32 could work, if we restrict some things (although still to reasonable values). We may consider using this if it turns out to be much faster and/or memory turns out to be a problem.
Conclusion
Float64, even if allowing for crazily big dimensions, has enough accuracy to allow for a considerable gap between smallest storable accuracy, and smallest permissible design resolution. Float32 actually also seems to have enough space, however there the restrictions on model size may become problematic.
For MacPy3D will start off by choosing bounds that can possibly be relaxed further later . We will allow 10⁹ as largest coordinates, 10⁻³ as design resolution (which means that if you create a model where distances are smaller than 10⁻³, you will at the very least get warnings), and 10⁻⁶ as ε.
Later these bounds could possibly be relaxed in the future, and/or we may allow options to use float32/float128.
Shapes in 3D
After all this introduction, we can finally talk about what this all means for our 3D shapes.
Let’s revisit the shapes we defined before in 2D space, and see what happens in 3D space.
- We can extend the 0D-0.1D-0.2D point/pointline/pointmap with a 0.3D pointcloud. We should note that, just as previously we said that a pointline with more than 2 points may not be an exact line anymore due to floating point precision (and therefore becoma a pointmap), it’s true in this case than anything with more than 3 points may become a pointcloud due to precision rounding.
- Lines also get a 1.3D variant (for which I don’t have a good name right now; linecloud?). Just, multiple lines whose coordinates do not lie in 1 plane.
- Polygons also get a 2.3D version (mesh; this term may need to be changed, see at the end of this article); multiple surfaces (faces) that lie in 3D space. They may or may not enclose a space, this is not important. The important thing is that they define surfaces in 3D space, whereas bodies (which we will encounter next) describe a volume in space. This is the same distinction as in 2D between a polyline (that may form a closed loop, but defines lines) and a polygon (which defines an area).
Note that as soon as a polygon in 3D space has more than 3 vertices, floating point rounding may make the points not al lie in exactly the same plane (which means that one could argue that the object is a bit misdefined then).
Obviously we now also need to add a 3D shape. 3D objects (or 3.3D objects) are called bodies. A body is a (defined) volume.
We discussed earlier that there are different ways to store shapes. You can store something similar to what we called “Shape representation” in 2D; e.g. “at location (x, y, z) we have a cube of size S, and we subtract from it a cylinder with radius R and length L rotated D degrees around axis A, …”. This is known as Constructive Solid Geometry (CSG). It has many advantages; one big disadvantage though is that you have to work out lots of interactions. For each set of 2 shapes, you have to create rules for how they interact.
The alternative representation, similar to line-representation in 2D, is called Boundary Representation, or B-Rep. In this case you specify only the border of the shape, even though what you actually care about is the body, the volume. As you remember, in case of the 2D line representation, we defined the system in such a way that one side of the line was always the inside of the polygon, and the other side the outside (e.g. left is inside, if you traverse the points in the order that they’re defined). We will do something similar in 3D.
In 3D, any volume is bounded by 2D polygons (if we ignore curved lines and surfaces) in 3D space (a 2.3D object). However, as we discussed above, extra work will have to be done to guarantee that polygons with more than 3 points stay in one 2D plane (if at all possible). Luckily, any valid polygon (see the section on polygons to see what is a valid polygon) can be deconstructed into triangles (polygons with 3 points, where all corners > 0) — note that such triangles always, by definition, lie in a single unique plane. So, in (our) boundary representation, a body is defined by a list of faces, each of which is a triangle in 3D space. Just as we need to define an “inside” with the line-representation in polygons, we choose an inside based on the orientation of the triangle: as we walk from point A to B to C, if we walk in clockwise direction, we’re looking at the outside of the border-face, if we walk counter clockwise, it’s the inside (in mathematical terms: the normal of the triangle, which is the cross product of (B-A) ⨉ (C-A) points towards the inside (or outside, whatever you choose, as long as you’re consistent)).
Just as with polygons, we now need to define some rules as to which bodies are valid, and just as with polygons, there are two reasons why they may be invalid: there is a shared face (like a shared edge); meaning the face between 3 vertices is defined twice, once in one direction, once in the other direction (meaning that either there is 0 gap in between, or 0 body in between), and the second reason is if distances become smaller than ε.
It’s a bit harder to show on this screen examples of 3D objects that are or are not valid, so you will need your imagination (or just trust me).
Note that the edge of a body (the faces) form a 2.3D object (mesh) by itself, just as the edge of a 2D polygon is a 1.2D polyline. Just as a polyline can only describe a valid polygon if it adheres to the three rules with described in the Polygons section, a mesh can only describe a valid body, if it adheres to these three rules:
- Each face (triangle) in the mesh is defined in an order (e.g A-B-C), and this order defines which side is inside and which side is outside (through the clockwise/anti-clockwise rule) — note that we said before that each triangle must have corners > 0; actually, we need to improve on that (because of floating point precision we can’t really define a corner of eactly 0), saying that that any point in the triangle may not lie within ε of a line through the other two points. Each edge in the mesh (edge is side of the triangles) is well-oriented (i.e. there are no inconsitencies, i.e. each point right next to the edge (not being on a triangle) is either between 2 triangles facing inwards, or 2 triangles facing outwards. This also means that each edge always has an even number of faces connected to it.
This implies no self-intersection. - Each vertex must be a minimal distance ε from any face that does not share this vertex — note that this implicitly guarantees (together with rule 1 and 3) that any two vertices are always at least ε apart, including having 2 vertices with the same coordinates. In addition, any two edges not sharing a vertex must have a minimal distance> ε between them — this is to catch the case where there is 1 horizontal line and 1 vertical line that come very close to each other, while their vertices are all far apart.
- Any set of 3 vertices can have at most 1 face between them — this disallows shared faces.
Manifoldness

Other programs seem to use the term “a manifold shape” to mean “a valid shape according to the rules I have”. Even though there is a good mathematical definition of what is a manifold, so far I have been unable to find a full description on what manifoldness means in different programs. Blender stack exchange has many questions about error messages related to it. It feels to me that much confusion can be avoided by making manifoldness an explicit part of your product (or library) — and then having very clear rules about how something can become non-manifold and being able to show exactly where that happens. So, for MacPy3D it should be clear: Any body is manifold, since something is only a body if it adheres to the 3 rules above. Alternatively, one can have a mesh object, a 2.3D object, in which case there are no rules whatsoever to adhere to. Obviously only some meshes can be upgraded to bodies (only when they are manifold).
Since I was unable to find the exact rules for other programs, it’s not possibly to give the differences between what MacPy3D considers manifold and what other programs consider so. One thing where I know that MacPy3D differs from Blender is that Blender supposedly doesn’t support edges with more than 2 faces defined, whereas MacPy3D does (sorry, I cannot embed an example, so you will have to imagine 2 cubes of size 1, one at (0, 0, 0) and one at (1, 0, 1) — and then merging these two cubes into 2 object. As far as I know this is not allowed in Blender whereas it should in MacPy3d).
Names
Here I name the shapes we talked about, mostly for my own future reference. Obviously we might introduce sub-categories (e.g. special polylines are ones that are head-to-tail, closed, or that define the border of a valid polygon), however this is a good start.
- 0.0D: point
- 0.1D: pointline
- 0.2D: pointmap
- 0.3D: pointcloud
- 1.1D: line, multi-line
- 1.2D: polyline
- 1.3D: unnamed (line-cloud?)
- 2.2D: polygon
- 2.3D: mesh (note: this might need a new name since mesh seems to be what we call a body)
- 3.3D: body, polyhedron
